

Um breve entendimento sobre o que não vemos nos bancos de dados

Introdução
Esse artigo é o primeiro de uma série de artigos que irei desenvolver sobre dicas e truques em SQL para pessoas que estão iniciando sua carreira na área de banco de dados, e essa vontade se deu, principalmente pelo fato de eu perceber que muitas faculdades e cursos, dificilmente dão a devida atenção para o banco de dados, que é o grande vilão silencioso de grande parte da lentidão dos sites e sistemas.
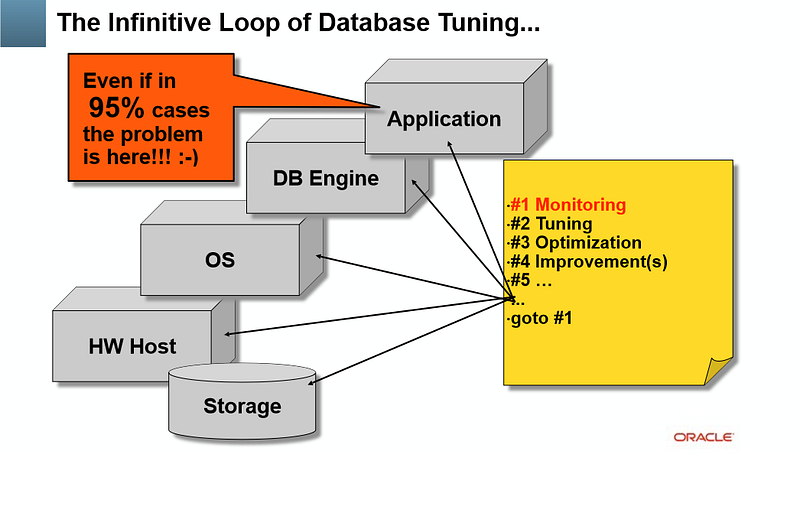
Segundo Dimitri Kravtchuk, arquiteto de performance Oracle, em sua apresentação sobre performance que você pode conferir aqui, diz que 95% dos problemas de lentidão estão sempre relacionados a camada de aplicação do software e não com os servidores e banco de dados.
E isso tudo ocorre, principalmente pela falta de experiência e conhecimento ( ninguém nasce sabendo das coisas ), e por esse motivo, indicarei aqui, alguns livros que me fizeram aprender as coisas de uma forma mais correta.
- Training Kit SQL — 70 461
- SQL Avançado — Teoria Relacional
- Aprendendo SQL
Pré Requisitos
- Conhecimento básico de banco e dados e queries.
O que é Structured Query Language ou SQL ?
A linguagem SQL é standard da ISO (International Organization for Standards) e ANSI (American National Standards Institute ) que continua em constante evolução ( última versão que eu acompanhei foi atualizado em 2011 )e é utilizada para manipulação de informações no banco de dados. Há casos em que nos deparamos com linguagens própria de cada banco de dados e que se assemelha muito com SQL pelo fato dela ser uma standard ISO, por exemplo o T-SQL da Microsoft e o PL/SQL da Oracle, por esse motivo, sempre:
- Prefira usar o standard, independente do banco de dados que vocês esteja usando. Só use o que não é standard por questões muito importante e que realmente te beneficiária, por outro lado, se um dia você precisar migrar de plataforma, menor será seu impacto se você estiver utilizando o SQL standard.
- Por exemplo, em T-SQL, ele aceita 2 tipos de “not equals” <> e != , a primeira é standard a segunda não.
SQL é baseado no modelo relacional matemático
O modelo relacional é um engano pois, para muitos, o banco é relacional pela relação das tabelas ( chaves estrangeiras ), porém o termo vem da matemática.
De acordo com o criador da teoria matemática , Georg Cantor “Sets é qualquer conjunto M de uma definição (total), objetos distintos m (que são chamados elementos de M) de nossa percepção ou nosso pensamento ”, ou seja, se M for um conjunto de carros, podemos dizer que todo carro contém pneus, vidros, portas, que são seus elementos m.
Por definição total: Consideramos que ninguém interage com um elemento apenas de uma set, ao contrário, interagimos com o todo, ou seja, dificilmente alguém usa um carro e só interage com o pneu.
Elementos distinto: Sets não tem duplicatas, ou seja, se nós afirmarmos umas verdade, não tornamos ela mais verdadeira. Se consideramos uma set de {a,b,c} podemos considerar igual a {a,a,b,b,c,c,}, ou seja, para o conjunto M ( carro ) podemos dizer que {volante,pneu,freio} é igual a {volante,volante,pneu,pneu,freio}.
Outro ramo que o modelo matemático é baseado, é a lógica dos predicado. Para filtrar, garantir integridade e etc… O modelo relacional usa a lógica dos predicados como um dos seus cores.
Exemplos de predicados:
- Salário maior que 5000;
- Idade maior que 20;
- Nome igual a ‘Larissa’;
A anatomia de uma query, como funciona um SELECT?
Agora que entendemos os conceitos básicos da matemática dos bancos, entraremos em um tema um pouco mais avançado, no qual espero que você tenha o mínimo de conhecimento sobre a execução de uma query. Falaremos agora sobre como funciona o SQL Engine, que é responsável por toda interpretação matemática na inserção e recuperação dos dados nos bancos.
Para explicar o passo-a-passo, vamos considerar a query abaixo como exemplo desse artigo, para explicar de forma metódica o que um SQL Engine efetuaria esse comando.
SELECT count(*) as quantidade, cidade
FROM estudantes
WHERE UF= ‘SP’
GROUP BY cidade HAVING count(*) > 1
ORDER BY cidade
1 — A ORIGEM ( FROM )
Como primeiro, o primeiro procedimento efetuado é a analise da origem dos dados, ou seja a TABELA onde estamos armazenando os dados, desconsiderando algumas exceções de configurações como paginação e quantidade de memoria alocada para queries, nesse passo a engine tenta recuperar o máximo possível de informação existente na tabela para uso posteriores, ou seja, mesmo com o filtro ( WHERE ) acionado, todas as linhas seriam recuperada para a memoria do servidor
2 — FILTRANDO O QUE É ESSENCIAL ( WHERE )
A segunda fase, consiste em filtrar as linhas que realmente fazem sentido para nós, para isso sinalizamos ONDE ( WHERE ) estão os dados que nós precisamos. Somente os valores que retornarem verdadeiro serão trazidos, respeitando assim a matemática da lógica dos predicados. Como sinalizamos na query acima, precisamos das linhas ONDE ( WHERE ) a UF fosse verdadeiro para o valor SP.
3 — AGRUPANDO RESULTADOS ( GROUP BY )
Nessa parte, lidamos com combinações de elementos da tabela de ORIGEM. Cada linha será agrupada (GROUP BY) conforme a regra de agrupamento imposta. A query que utilizamos, está agrupando (GROUP BY) por cidade, visualmente o exemplo seria

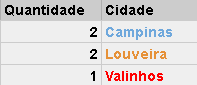
4 — FILTRANDO AS LINHAS COM HAVING ( HAVING )
Essa fase é responsável por filtrar dados, porém, só podemos usar HAVING depois que temos um AGRUPAMENTO já efetuado no resultado, ou seja, só utilizaremos o HAVING após um GROUP BY, ele avalia por GRUPO e filtra os dados considerando o AGRUPAMENTO como um todo. No nosso caso, o HAVING está usando um predicado de COUNT (*) > 1, ou seja, está filtrando os AGRUPAMENTOS por cidade que tenham (HAVING) mais de um dado repitido.
- Qual a grande diferença entre WHERE e HAVING? O WHERE avalia as linhas antes de serem agrupadas, já o HAVING apenas avalia um resultado agrupado
5 — EXIBINDO INFORMAÇÕES ( SELECT )
A quinta parte do processamento é responsável por TRAZER ( SELECT ) os dados, nessa fase, dividimos em 2 passos. O primeiro passo seria listar e retornar as colunas que precisamos exibir da tabela. O segundo passo é o uso de funções e tratamento de dados que podemos fazer para cada coluna individualmente, por exemplo a função COUNT() do nosso exemplo.
6 — POR ULTIMO, A ORDENAÇÃO ( ORDER )
Essa fase é aplicada opcionalmente, caso queremos ordenar a forma que será exibido o resultado, usamos a ORDENAÇÃO ( ORDER BY ) para efetuar esse trabalho.
No nosso caso, vemos que a ORDENAÇÃO ocorre por cidade. Pode ocorrer de você tentar ordenar uma coluna que tem alias, para esse caso , como estudamos acima, a ORDENAÇÃO ocorre após o SELECT, então a expressão ( alias ) já foi validada anteriormente e deverá ser utilizada no ORDER BY
Outro ponto importante de usar a ORDENAÇÃO, é que adiciona um custo a mais para o processamento da query, em casos que a ordem não é importante, é aconselhável não usar desnecessariamente a ordenação.
7 — Por fim, a execução
Azul, representando o comando e o Amarelo representando a execução.

CONCLUSÃO
Nesse primeiro momento, a ideia principal foi apresentar os aspectos matemáticos que são básicos para entendimento e operação dos bancos de dados e como funciona o SQL Engine na construção de uma query. Nos próximos artigos abordarei a matemática dos JOINS e outras estratégias para evitarmos cálculos desnecessários e usos exagerados de memória RAM no servidor.
Qualquer dúvida ou sugestão, entre em contato comigo ou via Telegram.
