
Durante minha experiência na área de desenvolvimento, percebi que muitos desenvolvedores ( até experientes ) tinham dificuldades de fazer queries, dificuldades não de criar a query em si, mas de realmente entender o funcionamento do SQL Engine, então eu percebia que sempre criavam validações desnecessárias/redundantes e queries sem performance nenhuma.
Em 2013, tive privilégio de conhecer meu professor Thiago Bergonsi, um dos melhores DBA’s e instrutores de cursos voltados para certificações SQL Server, e em uma de suas aulas, ele me explicou passo-a-passo o que um SQL Engine faz para retornar o resultado de um query e desde então mudou totalmente minha visão sobre fazer consultas em banco de dados.
Para explicar o passo-a-passo, vamos considerar a query abaixo como exemplo desse artigo, para explicar de forma metódica o que um SQL Engine efetuaria esse comando.
SELECT count(*) as quantidade, cidade
FROM estudantes
WHERE UF= ‘SP’
GROUP BY cidade HAVING count(*) > 1
ORDER BY cidade
1 — A ORIGEM ( FROM )
Como primeiro, o primeiro procedimento efetuado é a analise da origem dos dados, ou seja a TABELA onde estamos armazenando os dados, desconsiderando algumas exceções de configurações como paginação e quantidade de memoria alocada para queries, nesse passo a engine tenta recuperar o máximo possível de informação existente na tabela para uso posteriores, ou seja, mesmo com o filtro ( WHERE ) acionado, todas as linhas seriam recuperada para a memoria do servidor
2 — FILTRANDO O QUE É ESSENCIAL ( WHERE )
A segunda fase, consiste em filtrar as linhas que realmente fazem sentido para nós, para isso sinalizamos ONDE ( WHERE ) estão os dados que nós precisamos. Somente os valores que retornarem verdadeiro serão trazidos. Como sinalizamos na query acima, precisamos das linhas ONDE ( WHERE ) a UF fosse verdadeiro para o valor SP.
3 — AGRUPANDO RESULTADOS ( GROUP BY )
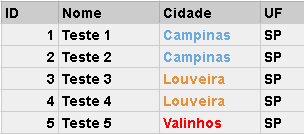
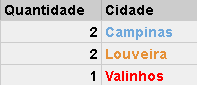
Nessa parte, lidamos com combinações de elementos da tabela de ORIGEM. Cada linha será agrupada (GROUP BY) conforme a regra de agrupamento imposta. A query que utilizamos, está agrupando (GROUP BY) por cidade, visualmente o exemplo seria
4 — FILTRANDO AS LINHAS COM HAVING ( HAVING )
Essa fase é responsável por filtrar dados, porém, só podemos usar HAVING depois que temos um AGRUPAMENTO já efetuado no resultado, ou seja, só utilizaremos o HAVING após um GROUP BY, ele avalia por GRUPO e filtra os dados considerando o AGRUPAMENTO como um todo. No nosso caso, o HAVING está usando um predicado de COUNT (*) > 1, ou seja, está filtrando os AGRUPAMENTOS por cidade que tenham (HAVING) mais de um dado repitido.
- Qual a grande diferença entre WHERE e HAVING? O WHERE avalia as linhas antes de serem agrupadas, já o HAVING apenas avalia um resultado agrupado
5 — EXIBINDO INFORMAÇÕES ( SELECT )
A quinta parte do processamento é responsável por TRAZER ( SELECT ) os dados, nessa fase, dividimos em 2 passos. O primeiro passo seria listar e retornar as colunas que precisamos exibir da tabela. O segundo passo é o uso de funções e tratamento de dados que podemos fazer para cada coluna individualmente, por exemplo a função COUNT() do nosso exemplo.
6 — POR ULTIMO, A ORDENAÇÃO ( ORDER )
Essa fase é aplicada opcionalmente, caso queremos ordernar a forma que será exibido o resultado, usamos a ORDERNAÇÃO ( ORDER BY ) para efetuar esse trabalho.
No nosso caso, vemos que a ORDENAÇÃO ocorre por cidade. Pode ocorrer de você tentar ordenar uma coluna que tem alias, para esse caso , como estudamos acima, a ORDENAÇÃO ocorre após o SELECT, então a expressão ( alias ) já foi validada anteriormente e deverá ser utilizada no ORDER BY
Outro ponto importante de usar a ORDENAÇÃO, é que adiciona um custo a mais para o processamento da query, em casos que a ordem não é importante, é aconselhavel não usar desnecessáriamente a ordenação.
CONCLUSÃO
Entender como é o processamento da Engine SQL é muito importante, principalmente para compreender o problema de uma forma mais visual. Seguindo esses passos com detalhes, saberemos criar queries para serem utilizadas da melhor forma. Para casos mais complexos como uso de Inner Joins por exemplo, aconselho utilizarem o recurso EXPLAIN que muitas ferramentas de desenvolvimento ( como PL/SQL Developer ou SQL Server Managment ) possuem para analisar o passo-a-passo que a query faz para gerar o resultado final.
Tem interesse em aprender mais sobre? Entre em contato conosco ❤️!
