

Experiências e ideias sobre rastreabilidade para desenvolvimento de software

Introdução
Gerando o pacote
Muito provavelmente você já se deparou com a marcação de Lote e Validade em um produto alimentício, essa marcação serve para você consumidor entender que esse produto tem uma margem segura para consumo e se eventualmente você acabar comprando um produto com algum problema, a empresa também consegue rastrear a origem desse produto para investigar as possíveis causas.
Dessa marcação, você pode extrair informações como:
- Validade: Apresenta para o consumidor a margem segura para o consumidor
- Lote:
1 — A empresa consegue rastrear de qual filial foi a origem do transporte, o dia da semana que foi produzido, mês, ano, horário.
2 — Toda empresa guarda uma contraprova do que foi produzido, se o problema foi na produção, com a contraprova é uma forma fácil de validar se o produto já saiu da empresa dessa forma
3 — Caso a contraprova esteja OK, a empresa pode sugerir uma auditoria na logística do transporte, verificando se atendeu todos os pré-requisitos para entrega do produto.
4 — Caso a contraprova não esteja OK, a empresa pode investigar internamente se o maquinário teve manutenções, limpeza correta e etc durante aquele dia.
Agora, imagine no cenário da indústria de software, sabendo que o seu serviço tinapet versão 1.0.0 acabou de apresentar problema em produção, como você faria a engenharia reversa do para identificar o lote problemático?
Nesse artigo, tentarei apresentar algumas sugestões para você implementar um processo de rastreabilidade na esteira de produção de um software.
Rastreabilidade para desenvolvimento de software
Durante um ciclo de release, a esteira CI/CD passa por algumas validações para garantir integridade da aplicação e durante essa fase podemos usar algumas estratégias para registrar algumas ocorrências como
Tudo começa do começo
Considerando que estamos controlando uma aplicação em NodeJS, sabemos que todo projeto Node começa pelo package.json. Esse arquivo é responsável por controlar a versão do seu projeto e todas as dependências que ele irá utilizar.
Você pode usar ferramentas como standard-version para aumentar de forma automágica a version do seu package.json a cada nova entrega que você fizer do seu software para o cliente, lógico, se você utilizar a convenção de versionamento semântico.
Esse é o primeiro passo para criarmos a rastreabilidade do seu sistema.
Gerando evidência
Durante a fase de CI de uma pipeline, os testes e validações de segurança normalmente podem exportar relatórios de suas execuções, com isso, podemos forçar que todos os relatórios possam ser gerados utilizando a mesma versão do gerenciador de pacotes do projeto (package.json, pom.xml e etc), como por exemplo:
- Relatórios dos testes devem ser gerados com versão-diamesano-hora
1.0.0-16102022-1500 - Relatórios podem ser armazenados em algum sistema de armazenamento temporário para controle
- Em alguns casos, ferramentas como CodeSense e Sonar permitem que você envie a versão junto do seu relatório, assim você também consegue manter o controle de qualidade do seu produto pelas versões que você está publicando.
Esse segundo passo é de grande importância, pois é uma forma de evidênciar que nosso software passou por algum controle de inspeção de qualidade ou segurança e gerou evidência dessas validações.
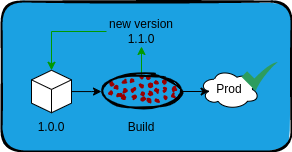
Gerando o pacote
Numa fábrica de qualquer produto, toda matéria prima se torna um produto final, numa pipeline de softwares não é diferente, eu poderia descrever vários tipos de artefatos que uma pipeline de software pode gerar no final do seu processo, mas acredito que poderia detalhar mais cenários em um artigo separado. Nesse caso, para uma pipeline de software, vamos considerar que nosso produto final seja ou uma imagem docker ou um lib commons ( bibliotecas genéricas que tem a função de serem compartilhadas em vários projetos, a biblioteca fs para nodejs é um exemplo ).
O ideal é que esse produto final seja armazenado em algum lugar. Se você está trabalhando com docker, o ideial seria que você tivesse o próprio Container Registry interno para armazenar essas imagens geradas, caso você esteja produzindo alguma biblioteca, o ideial seria publica-la em algum JFrog, Nexus ou Azure Artifact interno para controle e histórico de todas versões geradas. Com esse controle, fica fácil para você utilizar a versão do seu sistema para reproduzir algum bug sem ter que utilizar o ambiente de produção ou até mesmo em caso de uma crise, você consegue de forma fácil e ágil resgatar a ultima versão mais estável desse pacote e publica-lo novamente no ambiente.
Nessa terceira fase, temos algopalpável, um produto final.
Criando marcos
Após a criação desse pacote é essencial que a pipeline sempre gere um snapshot/marco no repositório usando a estratégia de git tag. Assim você terá controle dos momentos onde ela esteve estável ou não, além de poder resolver bug em qualquer versão e gera-la novamente para resolver os problemas do seu cliente final.
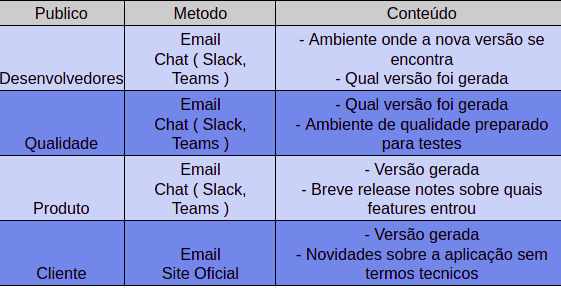
Comunique
Por fim, sempre comunique o produto final de sua pipeline para a audiência correta, usando os canais corretos.
Engenharia Reversa e considerações finais
Assim como através da numeração do produto uma empresa consegue Algumas dessas estratégias nos ajudam numa eventual necessidade de investigação caso o sistema venha apresentar algum problema você consegue fazer toda engenharia reversa por todas as evidências que essa versão gerou no processo de CI/CD.
Qualquer dúvida que você tenha para inserir esse processo de gerenciamento de pacote em sua esteira CI/CD entre em contato conosco ❤️!
