

No mundo digital de hoje, a capacidade de monitorar e observar sistemas é mais do que uma necessidade, é uma arte que distingue os verdadeiros heróis da engenharia de software do restante. Este artigo, o primeiro de uma série de quatro artigos, procura transformar iniciantes em mestres da observabilidade e monitoramento, começando com os fundamentos de Observabilidade e Monitoramento, que são a base de tudo. Nossa jornada é guiada pelo herói MetricMaster, que se aventura no vasto reino da tecnologia com a missão de dominar essas artes essenciais. Esse herói foi criado baseado na minha experiência profissional como SRE ao longo de quase 10 anos, então as coisas que ele abordar aqui não necessariamente são a verdade absoluta.
O Que é Observabilidade?
Observabilidade não é apenas um termo da moda é uma tecnologia de sistemas complexos que permite aos Engenheiros de Software de Cloud, DevOps e SRE (Site Reliability Engineer) entender o estado interno de um sistema a partir de seus outputs externos. MetricMaster aprende que, diferentemente do monitoramento, que são dados pré-definidos, a observabilidade é a capacidade de observar e se aprofundar no comportamento do sistema.
Por Que Observabilidade?
Num ambiente de TI onde mudanças são constantes e a complexidade só cresce, a observabilidade permite uma compreensão profunda e em tempo real do comportamento do sistema. MetricMaster sabe que a observabilidade permite as equipes prever e resolver problemas antes que eles afetem os usuários finais, garantindo uma experiência sem interrupções.
Pilares da Observabilidade
A observabilidade possui três pilares fundamentais: métricas, logs e traces. MetricMaster descobre que cada pilar é uma ferramenta poderosa em sua jornada, fornecendo uma visão holística do sistema:
- Métricas: Dados agregados que representam o estado do sistema ao longo do tempo. Métricas são dados conhecidos, ou seja pré-definidos, e capazes de ser mensuráveis ao longo do tempo, como por exemplo a CPU, memória, taxa de erro e latência de um sistema.
- Logs: Registros imutáveis de eventos ou ações que ocorreram dentro do sistema. Logs são dados não-lineares e não-constantes ao longo do tempo, diferente das métricas, pois os logs só são gerados caso haja um evento automático ou utilizacão do sistema.
- Traces: Representações das jornadas de requests HTTP individuais ou transações através do sistema. Assim como os logs, são dados não-constantes pois para um trace ser gerado é necessário que haja uma requisição HTTP manual ou automática feita pelo usuário ou alguma automação na aplicação web.
Monitoramento vs. Observabilidade
MetricMaster aprende a diferença fundamental entre monitoramento e observabilidade no mundo de Cloud, DevOps e SRE. Enquanto o monitoramento foca em métricas pré-definidas de forma proativa, a observabilidade permite uma compreensão mais profunda do sistema, explorando de modo reativo dados desconhecidos, como logs e traces.
Pense em monitoramento como a telemetria ou o dado que já conheçø e consigo coletar, como a temperatura num dia ensolarado, ou a pressão dos pneus do seu veículo. Já a observabilidade são aqueles dados que você precisa ler, analisar, entender e decifrar, como por exemplo a previsão do tempo que analisa uma série de dados para prever padrões, ou quando o motor do seu carro dá problema e o você tem que abrir o capô pra olhar os sinais e analisar oq eu aconteceu.
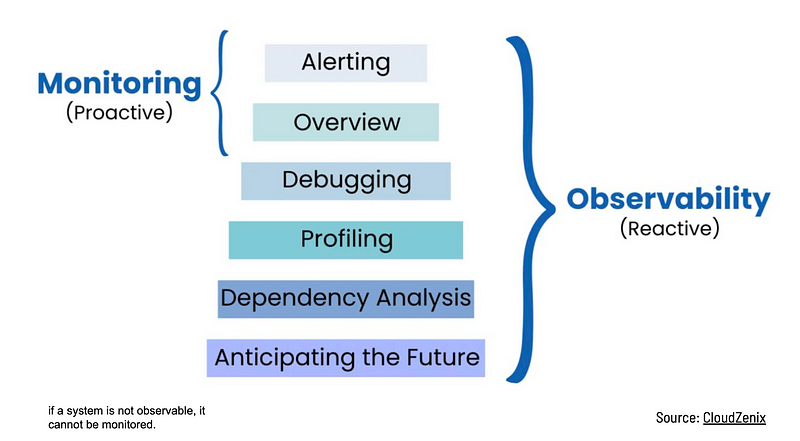
O Google SRE esclarece que monitoramento é uma ferramenta para observar e entender o estado dos sistemas através de métricas ou logs predefinidos. Por outro lado, observabilidade é uma abordagem mais dinâmica, permitindo as equipes realizar troubleshooting ativamente de seus sistemas por meio da exploração de padrões e propriedades não previamente definidos. Enquanto o monitoramento foca em métricas pré-definidas, como latência e uso de CPU/memória e taxas de erro, a observabilidade permite uma compreensão mais profunda do sistema, explorando métricas desconhecidas, logs e traces. Isso justifica a referência a observabilidade como “monitoramento 2.0” ou a referência de que monitoramento é parte da observabilidade, como mostra a imagem da CloudZenix.
A Importância da Observabilidade e do Monitoramento
“Sem monitoramento, estamos voando às cegas.” Essa afirmação é importante no mundo da tecnologia, onde aplicativos e sistemas complexos operam como aviões em pleno voo. Sem os dados fornecidos por métricas, logs e traces, os engenheiros de software são como pilotos de avião sem radar, sem dados de altitude, sem visibilidade — navegando sem uma compreensão clara de onde estamos ou para onde estamos indo. É nesse cenário que a observabilidade e o monitoramento emergem como os instrumentos essenciais que permitem aos engenheiros de DevOps e SRE não apenas voar, mas navegar pelo complexo mundo do troubleshooting e otimização de softwares com confiança e precisão.
Construindo um Sistema Observável — Fundamentos chave
Para tornar um sistema efetivamente observável, é essencial adotar uma abordagem multifacetada que vai além da simples coleta de dados. Aqui estão os passos fundamentais aprendidos por nosso herói MetricMaster durante sua jornada de estudo e entendimento de Observabilidade.
- Definição de SLIs e SLOs: Estabeleça Indicadores de Nível de Serviço (SLIs) e Objetivos de Nível de Serviço (SLOs) claros para quantificar a experiência do usuário e as metas de desempenho do sistema.
- Instrumentação Adequada: Implemente a coleta de dados detalhada por meio de instrumentação, garantindo que métricas, logs e traces estejam disponíveis para análise.
- Cultura de Aprendizado Contínuo: Promova uma cultura que valoriza a investigação contínua e o aprendizado a partir dos dados, incentivando a equipe a explorar as causas raízes dos problemas e a buscar melhorias constantes.
- Utilização de AIOps: Aplique soluções de AIOps para automatizar a detecção e a resolução de problemas, melhorando a eficiência na gestão de incidentes.
- Correlação de Dados: Desenvolva capacidades para correlacionar diferentes tipos de dados (métricas, logs, traces) para obter insights mais profundos sobre o comportamento do sistema.
- Framework MELT: Adote o framework MELT (Métricas, Eventos, Logs, Traces) para uma abordagem abrangente da coleta de dados, garantindo que todos os aspectos do sistema sejam monitorados e observáveis.
- Foco nos 4 Golden Signals: Concentre-se nos 4 sinais de ouro do monitoramento (latência, tráfego, erros, saturação) para manter uma visão clara da saúde do sistema.
Conclusão
Este artigo apenas arranha a superfície do que é necessário para dominar a arte da observabilidade e monitoramento. No entanto, compreender esses fundamentos é o primeiro passo crítico na jornada de qualquer Engenheiro de Software que queira se tornar um herói em Cloud, DevOps e SRE. Fique atento aos próximos artigos desta série, onde mergulharemos mais fundo em estratégias, práticas e ferramentas para aprimorar sua jornada de observabilidade e monitoramento. o próximo artigo, a Parte 2, MetricMaster vai mergulhar em “Estratégias que Funcionam” para levar sua habilidade de observabilidade ao próximo nível. Na Parte 3, exploraremos a gestão de incidentes, alertas e troubleshooting. Na parte final, abordamos as ferramentas e tecnologias essenciais, onde MetricMaster vai classificar as melhores do mercado e discutindo como elas podem potencializar suas práticas de observabilidade e monitoramento.
