

Após estabelecer os fundamentos de observabilidade e monitoramento na Parte 1, MetricMaster avança em sua jornada, explorando estratégias avançadas que transformam dados brutos em insights acionáveis. Nesta fase, nosso herói descobre como o framework MELT, os 4 Golden Signals e os conceitos de SLX (SLI/SLO) funcionam como a base para se alcançar a observabilidade.
Explorando o MELT e os Pilares da Observabilidade
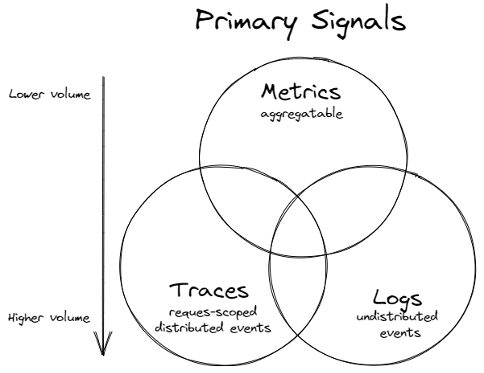
O framework MELT é uma das bases da observabilidade, que por sua vez tem seus pilares em metricas, logs e traces. O MELT descreve Métricas, Eventos, Logs e Traces para fornecer uma visão abrangente do sistema.
- Métricas: Imagine o uso de CPU e taxa de erros como termômetros do desempenho do seu sistema. As métricas são agregações numéricas de dados medidos regularmente ao longo do tempo que oferecem uma visão de alto nível do estado operacional. Métricas são dados conhecidos, ou seja pré-definidos, e capazes de ser mensuráveis ao longo do tempo.
- Eventos: São os batimentos cardíacos do seu sistema. Cada login de usuário ou notificação de alerta é um evento, marcando ocorrências discretas que podem indicar mudanças significativas ou problemas emergentes. Em outras palavras, eventos são ocorrências discretas com carimbo de tempo e valores numéricos, que nos permitem rastrear eventos cruciais e detectar possíveis problemas relacionados a uma solicitação do usuário. Esses eventos são algo que aconteceu em um sistema em um determinado momento. Os principais tipos de eventos são Logs e Traces.
- Logs: Os diários de bordo do seu sistema, detalhando o que aconteceu e quando. Desde um registro textual simples até estruturas complexas como JSON, os logs são indispensáveis para a depuração. Um log de evento é um registro imutável cque possui um carimbo contendo data/hora de eventos discretos ao longo do tempo.
- Traces: Os rastreadores das jornadas de request, mostrando o caminho completo que uma transação ou pedido faz através dos serviços distribuídos. Eles são cruciais para entender latências, gargalos e falhas no sistema.
A imagem abaixo da Microsoft mostra a diferença e interseção entre os pilares da observabilidade: Métricas, Logs e Traces (Eventos).
Dominando os 4 Golden Signals
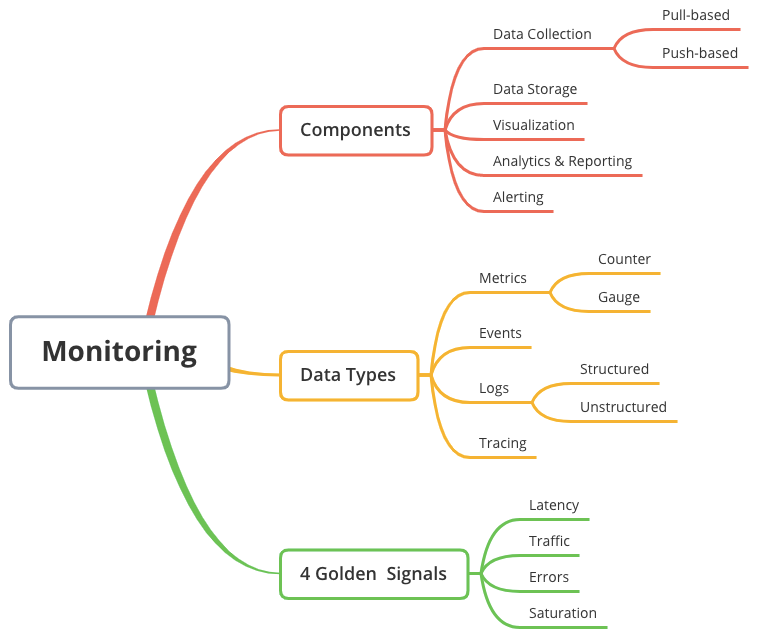
Os 4 Golden Signals, ou 4 sinais dourados da monitoração, fornecem uma bússola para manter a saúde do sistema em cheque:
- Latência: O tempo de resposta de uma solicitação. É o primeiro indicativo de uma experiência de usuário degradada.
- Tráfego: A demanda sobre seu sistema. Monitorar o tráfego ajuda a identificar padrões de uso e antecipar escalonamentos necessários.
- Erros: A taxa na qual as solicitações falham. Uma alta taxa de erros pode indicar problemas subjacentes graves.
- Saturação: Quão “cheio” seu serviço ou recurso está. Monitorar a saturação é essencial para evitar degradação do desempenho e falhas do sistema.
O Google diz que se você não sabe o que monitorar em seu sistema, inicie pelos 4 sinais de ouro do monitoramento e observabilidade. Portanto, essas métricas são a base. A imagem da KnowledgeShop aborda os componentes chave do monitoramento e observabilidade.
SLX e a Arte do Equilíbrio
SLX — abrangendo KPIs, SLIs, SLOs, e SLAs — oferece um quadro para medir e garantir a qualidade do serviço.
- KPIs (Key Performance Indicators) são as metas de alto nível que sua equipe se esforça para alcançar, como número de releases por mês.
- SLAs (Service Level Agreements) representam os compromissos com seus clientes, como um uptime de 99,99% prometido pela AWS para o EC2.
- SLIs (Service Level Indicators) e SLOs (Service Level Objectives) são o coração da engenharia de confiabilidade. Por exemplo, se o SLI é a disponibilidade do seu software, o SLO pode ser a meta de 99,99% de disponibilidade.
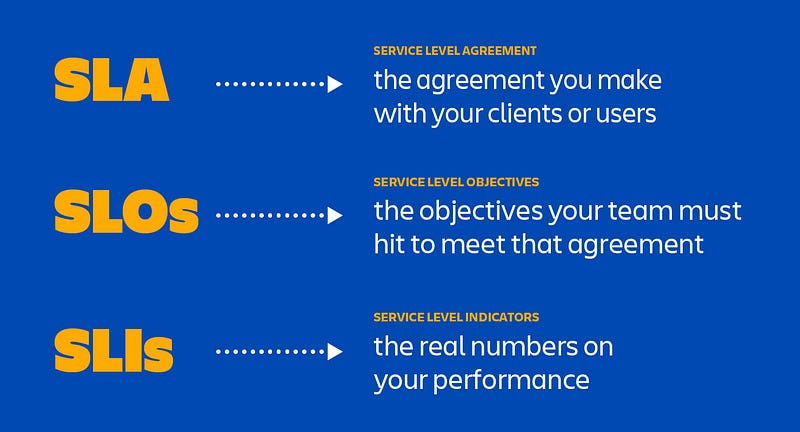
Para entender como MetricMaster equilibra inovação e estabilidade, é crucial diferenciar SLI, SLO e SLA:
- SLI é uma medida específica de algum aspecto do nível de serviço fornecido, como a disponibilidade ou tempo de resposta do seu software. Pense neles como os indicadores vitais do sistema.
- SLO é o objetivo definido para o SLI, o alvo que você se esforça para alcançar. É uma expressão quantitativa da meta de desempenho desejada, como manter a disponibilidade do software em 99,99%.
- SLA é um contrato com os clientes que define os níveis de serviço esperados, incluindo as consequências para o provedor de serviços se os SLOs e SLIs não forem atendidos. SLAs são acordos formais que muitas vezes têm implicações legais e financeiras.
A imagem abaixo da Atlassian aborda essas diferenças de uma maneira mais visual.
Error Budget: Equilibrando Inovação e Estabilidade
O Error Budget é uma ferramenta fundamental na engenharia de confiabilidade do site, fornecendo uma métrica quantitativa da margem de erro permitida sem violar os SLOs. Se o seu SLO de disponibilidade é de 99,99%, isso significa que você tem um Error Budget de 0,01% para gastar com inovações, atualizações e desenvolvimento, como aborda a imagem abaixo de um BEES Talks no Youtube. Monitorar seu Error Budget ajuda a equilibrar o lançamento de novas funcionalidades com a manutenção da estabilidade operacional.

Conclusão
Esta etapa da jornada de MetricMaster nos ensina a importância de entender e aplicar estratégias avançadas de observabilidade e monitoramento. O domínio do MELT e dos 4 Golden Signals, junto com uma compreensão profunda dos SLX e o gerenciamento inteligente do Error Budget, são pedras angulares para qualquer profissional dedicado a manter sistemas robustos e resilientes. Essas práticas não só garantem a satisfação do usuário final mas também promovem uma cultura de inovação responsável dentro das equipes de tecnologia. À medida que MetricMaster continua sua jornada na Parte 3 — Solução de Problemas de Software — Gestão de Incidentes, Alertas, Troubleshoot, AiOps e PostMortem — ele nos lembra que a verdadeira maestria em observabilidade e monitoramento vem da aplicação cuidadosa desses princípios, equilibrada com a coragem de inovar.
