

Nested Loops, o terror da performance!
Neste artigo, irei abordar sobre o passo a passo do comando JOIN, os erros mais comuns que cometemos com performance e algumas soluções práticas. Para isso, irei considerar que você:
- Conhece o conceito básico de SQL e Queries
- Ou já leu meu primeiro artigo da série sobre performance.

O que é um JOIN?
No SQL Engine, o comando JOIN serve para serve para criar relacionamento entre dados, por exemplo se você pegar uma tabela A que tem dados associados com uma tabela B, o comando join será responsável por auxiliar nessa relação entre os dois dados das tabelas, essa operações irá usar a lógica dos predicados para associar os dados entre as tabelas correspondentes para apresentar.
Tipos de JOINS
A matemática dos JOINS — Álgebra Relacional
Essa operação é responsável por agrupar informações provenientes de duas tabelas distintas, no qual, se relacionam por algum dado em comum. Ou seja, usamos esse comando para nos trazer dados, por exemplo de uma tabela de Pedido e outra de Itens do Pedido. Porém, poucos sabem é como esse operação procede matematicamente.
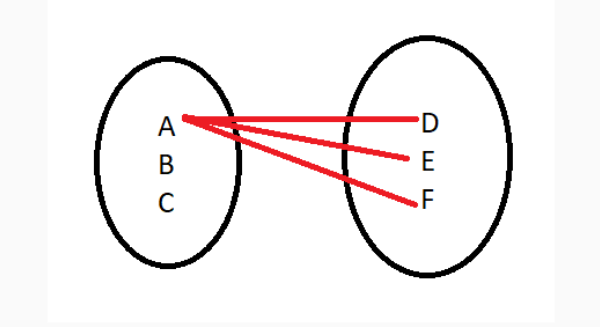
A operação matemática que representa o JOIN é chamada de Álgebra Relacional, ou seja, para cada linha da tabela A iremos comparar com a tabela B, ou seja, se a tabela A tem 10 linhas, e a tabela B tem 100 linhas, teremos uma operação de 1000 comparações, em outras palavras é um algoritmo que exponencia sua operação conforme a quantidade de dados e isso pode ser uma grande pedra no sapato se não soubermos o que estamos fazendo e para isso mostrarei passo a passo como podemos validar a performance de nossas queries.
Analisando minha query usando o EXPLAIN
Explain é um recurso que pode nos auxiliar no entendimento da execução de uma query. Esse recurso trás informações de tempo de execução, quantidade de linhas lidas e se houve uso de index ou não no processo de leitura das informações é executa-lo conforme exemplo abaixo:EXPLAIN SELECT * FROM TABELA;
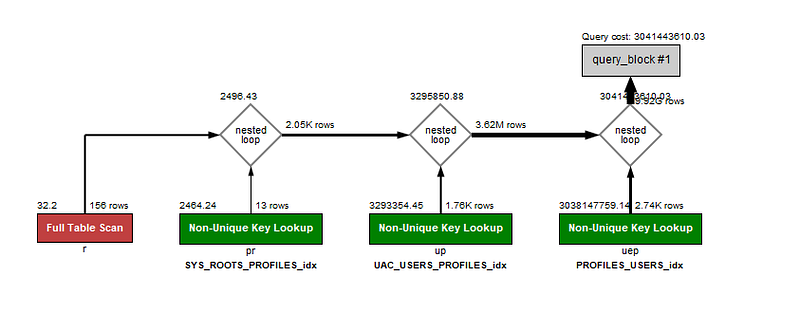
Usando o EXPLAIN em uma query que inclui 3 JOINS, conseguimos analisar e tirar algumas conclusões de como nossa query está se comportando, no exemplo acima, percebemos:
- A cada INNER JOIN, teremos um NESTED LOOP, esse algoritmo seria equivalente a álgebra relacional, ou seja, será efetuado uma comparação linha por linha das tabelas.
- Que tivemos um salto exponencial de 2.05K de linhas para 3.62M linhas e depois uma multiplicação exponencial que gerou 9.92G de linhas. Mas como e por que aconteceu isso?
A matemática dos JOINS ( Álgebra Relacional )

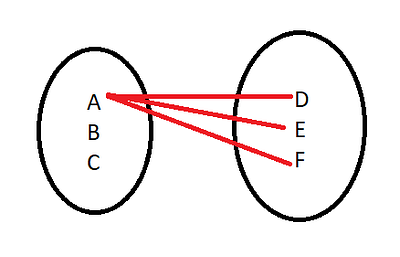
Quando utilizamos qualquer tipo de JOIN, internamente, esse algoritmo percorre cada linha de uma tabela, por exemplo a T1 da imagem acima e compara com cada linha da tabela T2, assim como mostrado na imagem ilustrativa do tópico, porém, se utilizarmos mais uma nova tabela para comparação, o resultado da quantidade de operações realizadas nesse comando exponenciaria conforme com a quantidade de linhas de dados que a nova tabela tem. Ou seja, a cada tabela que colocamos para interagir na operação JOIN, aumentará a quantidade de comparações e consequentemente exigirá mais processamento do banco de dados.
Para reduzir esse número de comparações e tornar nossos comandos mais leves, podemos utilizar as seguintes estratégias:
Semi-Joins
Para este cenário, imagine que você tem 100 dados na tabela T1 e queira validar com dados na tabela T2, mas não há necessidade de comparar linha por linha com a tabela T2, podemos utilizar a estratégia de semi-joins, essa operação consiste em você utilizar a regra do JOIN como filtro WHERE:SELECT T1.* FROM T1 WHERE T1.id IN ( SELECT T2.id_t1 FROM T2 where T2.UF = ‘SP’ )
Vantagens:
- É menos custoso a nível uso de recursos do servidor, pois compararemos os dados de T1, apenas com os dados já filtrados de T2
- É mais rápido a entrega de resultado dessa query, pelo fato que, ao compararmos T1.id com o resultado da subquery, se por ventura esse dado estiver já na seguna linha de resultado, não precisaremos percorrer linha por linha como o JOIN faz
- Em uma escala exponencial de uso da memória do servidor, como mostrado no tópico anterior, essa operação poderá reduzir muito não só o tempo de resposta mas também o uso de memória, pois haverá pouca informação para ser comparada
Desvantagens:
- Nesse caso, como estamos usando a tabela T2 já processada, não conseguimos utilizar o restultado dela para exibição.
Quero conferir só conferir se o dado se existe em uma outra tabela
Este cenário, é idêntico ao anterior, só que nesse caso iremos comparar os dados com a tabela T2 com os id’s da tabela T1, e trocaremos a validação IN por EXISTS:SELECT T1.* FROM T1 WHERE EXISTS( SELECT 1 FROM T2 where T2.UF = ‘SP’ AND T2.id_t1 = T1.id)
Vantagens:
- É menos custoso a nível uso de recursos do servidor, comparado com a operação JOIN, pois compararemos os dados de T1, apenas com os dados já filtrados de T2
- É mais rápido a entrega de resultado dessa query, pelo fato que, ao utilizarmos o EXISTS, ele apenas validará se o dado de T1 existe na tabela T2, mesmo que isso retorne mais de uma linha
Desvantagens:
- A subquery é executada sempre para cada linha de T2, isso torna o método ineficiente comparado com a estratégia anterior
- Nesse caso, como estamos usando a tabela T2 já processada, não conseguimos utilizar o restultado dela para exibição.
Quero trazer apenas um dado da tabela relacionada
Imagine que dentro da tabela T2, haverá 20 colunas, mas você só terá necessidade a real necessidade de exibir apenas um dado, para isso, ao invés de comprar linha por linha e ainda trazer todos os dados para depois exibirmos, podemos efetuar a seguinte logica:SELECT T1.*,
(SELECT T2.CITY FROM T2 where T2.UF = ‘SP’ AND T2.id_t1 = T1.id ) AS RESULT
FROM T1
Vantagens:
- É menos custoso a nível uso de recursos do servidor, pois, não estamos necessitando de todas as informações da tabela T2, apenas de uma coluna
- Caso a tabela T2 tenha pouco dados, essa operação se torna muito eficiente
Desvantagens:
- A subquery é executada sempre para cada linha de T2, isso torna o método ineficiente se a tabela T2 conter milhares de linhas, isso acaba tornando a operação inviável
- Nesse caso, como estamos usando solicitando apenas uma coluna, se precissásemos de mais informações, precisariamos concatenar o restulado ou criar nova subquery, o que tornaria tambem inviável se precissásemos de muitas informações.
Tabelas derivadas e a dicotomia problemática
Essa estratégia, basicamente é a junção de todos os conceitos ditos até agora. Segundo a teoria do sistemas de informação, um problema em si, pode contar universos sistemáticos interligados, então para isso, devemos sempre reduzir nosso sistema em partes menores (dicotomia) para resolução de qualquer problema. Há várias formas de você pensar nessa solução, eu geralmente utilizo os 3 por ques para identificar o problema central de algo e em banco de dados podemos utilizar a mesma lógica para resolvermos problemas complexos, só que ao invés de peguntar o 3 por ques, podemos utilizar tabelas derivadas:SELECT T1.*, T2_AUX.*
FROM T1
INNER JOIN (SELECT T2.* FROM T2 where T2.UF = ‘SP’) AS T2_AUX
ON T2.id_t1 = T1.ID
Vantagens:
- É menos custoso a nível uso de recursos do servidor, pois, não precisaremos comprar todas as linhas da tabela T2 do JOIN
- Podemos customizar várias queries e utilizarmos como tabela, simplesmente aplicando como uma subquery no FROM
- Podemos acessar os dados retornados pela tabela T2
- Diminuiçao do problema como um todo, como está escrito no inicio do artigo, se a tabela T1 tem 100 linhas e T2 também, um JOIN custaria em retorno de 10000 comparações, já com uma tabela derivada, podemos filtrar e reduzir as linhas da tabela T2 para ser comparada com T1
Desvantagens:
- A query fica enorme, e pode a longo prazo ficar fora do controle o uso de subqueries no FROM
- Caso seja utilizado um filtro mais elaborado, group by’s e até mesmo order by e a tabela utilizada tenha muita informação, essa operaçao pode acabar ficando mais custoza que a execução de um inner join linha por linha.
Essas foram algumas das sugestões de melhoria do desenvolvimento de uma query, que necessita relacionar informações de duas tabelas e está longe de serem as únicas e as melhores soluções para os exemplos que dei, por isso, sugiro sempr que devemos analisar caso a caso, testando todas as formas possíveis de comparações. No próximo artigo, falarei sobre algumas dicas configurações.
Tem interesse em aprender mais sobre? Entre em contato conosco ❤️!
