


Introdução
Uma vez me aventurei a ler os contos de Mil e uma noites arabes e encontrei uma história interessante sobre uma pessoa que encontrou um liquido que se aplicado aos olhos ela conseguia ver temporáriamente todos os tesouros escondidos embaixo da terra. Na ânsia de ver mais tesouros e por mais tempo ele virou o frasco inteiro em seus olhos e acabou ficando cedo.
No mundo da tecnologia, estamos vivendo em uma época em que os recursos computacionais são fáceis de serem encontrados e a um preço barato, se seu celular não te atende no quesito fotografia você consegue um outro melhor fácil, se o espaço em disco não consegue guardar todas as fotos que você tira você pode comprar recursos externos, onlines ou até mesmo um novo celular com o dobro de capacidade mas sem custar o dobro do que você pagou no primeiro e tudo isso há havia sido pela Lei de Moore, onde ela sinalizade que os recursos computacionais estão dobrando sua capacidade em um determinado período de tempo.
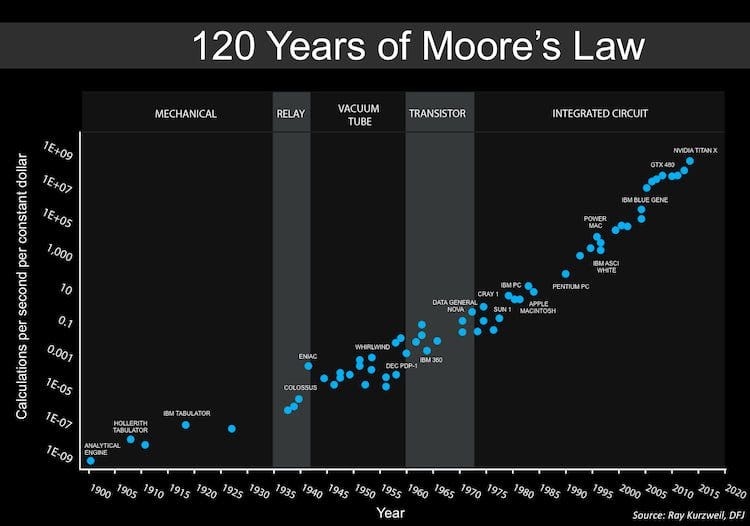
Como os recursos são utilizados ?
Todas as vezes que precisamos de um dado em uma tabela do banco de dados, a maquina responsável por manter o banco de dados ativo lê os dados das tabelas ( que estão armazenados no HD ) e os carregam na memória RAM da máquina.

Mas isso significa que se eu fizer uma query gigante ela vai requisitar memória de forma infinita? A resposta é NÃO! Por mais que hoje seja barato requerir mais recurso computacional para uma operação, todos os bancos SQL contém um recurso query-pagination esse recurso é responsável por controlar a quantidade de dados que serão disponibilizados como se fossem páginas de pesquisas, dentro de cada paginação de pesquisa ela retorna a quantidade máxima de dados permitida.
E como eu faço para otimizar o resultado das minhas queries?
Além da forma que você constrói as queries, conforme apresentado nos artigos anteriores, temos um outro vilão silencioso nesse processo, e eles são os tipos de dados que escolhemos para as tabela.
Toda linguagem de programação ou banco de dados contém os tipos de dados disponíveis e quanto de memória cada um desses dados ocupará sua maquina, como a tabela de exemplo abaixo.
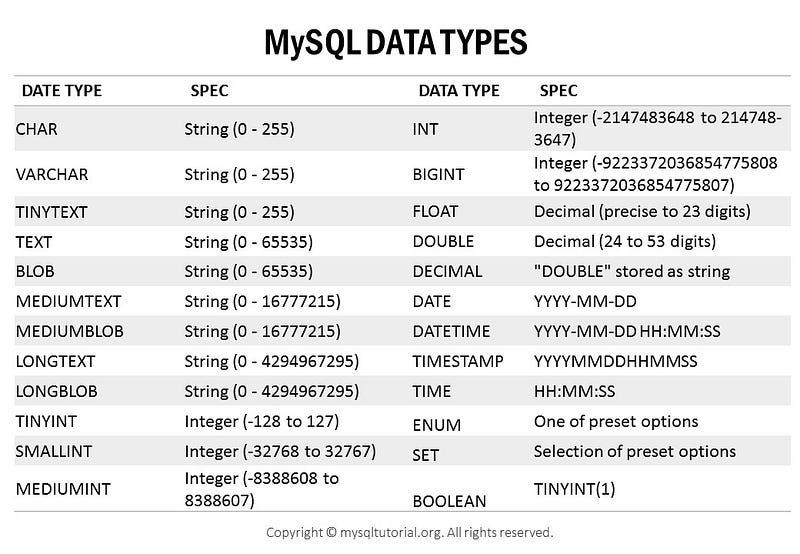
Vamos imaginar que temos uma tabela de cadastro de clientes que contém 100 mil linhas de informações, e uma dessas colunas serve para armazenar o estado cívil da pessoa.
CHAR
Se utilizássemos o tipo CHAR(15) , calcularíamos a quantidade de uso da seguinte forme:CHAR(15) = M × w bytes
Se a palavra armazenada for solteiro para todas as linhas seria o equivalente a 15 x 8 = 120 bytes
Se for levar em consideração as 100 mil linhas cadastradas, só para essa coluna seria equivalente a 12Mbs!
Se mudássemos para VARCHAR(15)VARCHAR(15) = L + 1 bytes if column values require 0 − 255 bytes
Se a palavra armazenada for solteiro para todas as linhas seria o equivalente a 8 + 1 = 9 bytes, multiplicado por 100k seria 9Mbs!
Se mudássemos para INT(1) e criássemos uma lógica como: “1 — Solteiro, 2 — Casado” e por aí em diante, o cenário assim:INT(1) = 4 bytes
Já que inteiro consegue atingir um rang entre -2147483648 a 2147483648 acaba consumindo 4 bytes por linha, independente do número que você coloque. Isso nos retornaria em torno de 4Mbs de informação.
Se mudássemos para TINYINT(1) que representa apenas números entre -127 até 127TINYINT(1) = 1 byte
Isso nos retornaria em torno de 1Mbs de informação.
Com apenas um exemplo, vimos como uma boa arquitetura na escolha dos tipos dados pode nos auxiliar e prevenir problemas de performance conforme o sistema cresce de forma exponêncial.
Referências
Tem interesse em aprender mais sobre? Entre em contato conosco ❤️!